/“旨在使万亿参数人工智能民主化。”
Nvidia 必不可少的 H100 AI 芯片使其成为一家市值数万亿美元的公司,其市值可能超过 Alphabet 和亚马逊,竞争对手一直在努力追赶。但也许 Nvidia 即将扩大领先优势——凭借新的 Blackwell B200 GPU 和 GB200“超级芯片”。

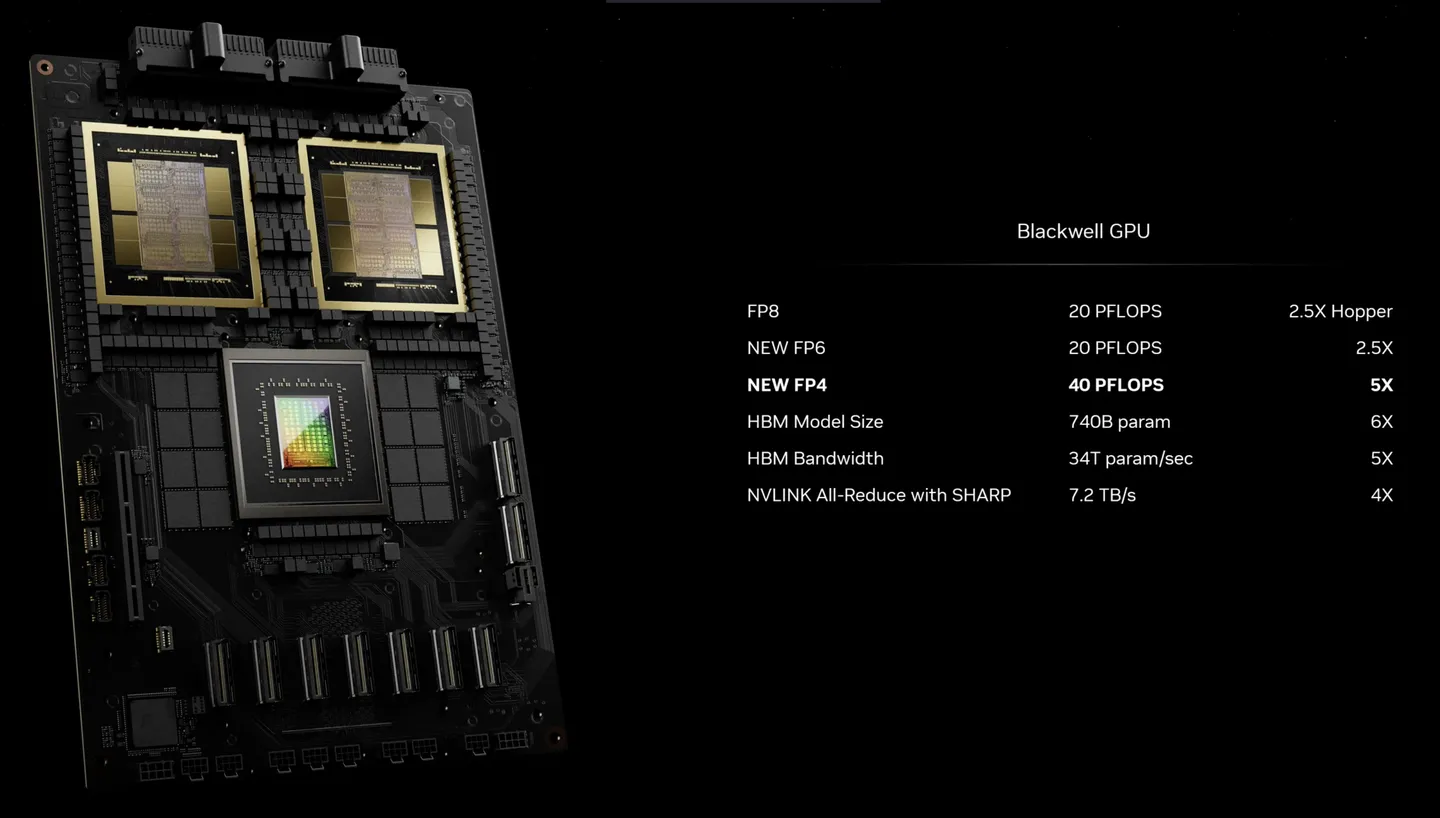
Nvidia 表示,新款 B200 GPU 拥有 2080 亿个晶体管,可提供高达 20 petaflops的 FP4 马力。此外,它表示,将两个 GPU 与单个 Grace CPU 相结合的 GB200 可以为 LLM 推理工作负载提供 30 倍的性能,同时还可能显著提高效率。Nvidia 表示,与 H100 相比,它“将成本和能耗降低了 25 倍”。
Nvidia 称,训练一个 1.8 万亿参数的模型之前需要 8,000 个 Hopper GPU 和 15 兆瓦的电力。如今,Nvidia 的首席执行官表示,2,000 个 Blackwell GPU 就可以做到这一点,而且仅消耗 4 兆瓦的电力。
Nvidia 表示,在具有 1750 亿个参数的 GPT-3 LLM 基准测试中,GB200 的性能仅为 H100 的七倍,而 Nvidia 表示它的训练速度是 H100 的四倍。

Nvidia 称,其中一项关键改进是第二代 Transformer 引擎,该引擎通过为每个神经元使用 4 位而不是 8 位(因此,我之前提到的 FP4 的计算速度为 20 petaflops),将计算、带宽和模型大小翻了一番。第二个关键区别只有在将大量 GPU 连接起来时才会出现:下一代 NVLink 交换机可让 576 个 GPU 相互通信,双向带宽为每秒 1.8 TB。
这要求 Nvidia 构建一个全新的网络交换芯片,该芯片拥有 500 亿个晶体管和一些自己的板载计算能力:3.6 万亿次浮点运算的 FP8,Nvidia 表示。
Nvidia 表示,此前,仅由 16 个 GPU 组成的集群会花费 60% 的时间相互通信,而只有 40% 的时间用于实际计算。
当然,Nvidia 希望公司能够大量购买这些 GPU,并将其封装在更大的设计中,例如 GB200 NVL72,它将 36 个 CPU 和 72 个 GPU 插入单个液冷机架中,总共可实现 720 千万亿次浮点运算的 AI 训练性能或 1,440 千万亿次浮点运算(即 1.4 百亿亿次浮点运算)。它内部有近两英里长的电缆,共有 5,000 条独立电缆。

机架中的每个托盘都包含两个 GB200 芯片或两个 NVLink 交换机,每个机架有 18 个 GB200 芯片和 9 个 NVLink 交换机。总体而言,Nvidia 表示其中一个机架可以支持 27 万亿参数模型。据传,GPT-4 的参数模型约为 1.7 万亿。
该公司表示,亚马逊、谷歌、微软和甲骨文都已计划在其云服务产品中提供 NVL72 机架,但目前尚不清楚他们购买的数量。
当然,Nvidia 也很乐意为公司提供其余的解决方案。这是用于 DGX GB200 的 DGX Superpod,它将八个系统合二为一,总共有 288 个 CPU、576 个 GPU、240TB 内存和 11.5 exaflops 的 FP4 计算能力。

Nvidia 表示,其系统可扩展到数万个 GB200 超级芯片,并通过其新的 Quantum-X800 InfiniBand(最多可容纳 144 个连接)或 Spectrum-X800 以太网(最多可容纳 64 个连接)连接在一起,形成 800Gbps 网络连接。
我们预计今天不会听到有关新游戏 GPU 的任何消息,因为这个消息来自 Nvidia 的 GPU 技术大会,该大会通常几乎完全专注于 GPU 计算和 AI,而不是游戏。但 Blackwell GPU 架构也可能为未来的 RTX 50 系列台式机显卡提供支持。
发表回复